I am a student who is highly passionate about Machine learning and AI.
I am a very curious person deeply in love with the advancement of Science and Technology.
I study Robotics at RWTH Aachen University, Germany. I like to Code and CAD.
I made this website to showcase my projects.
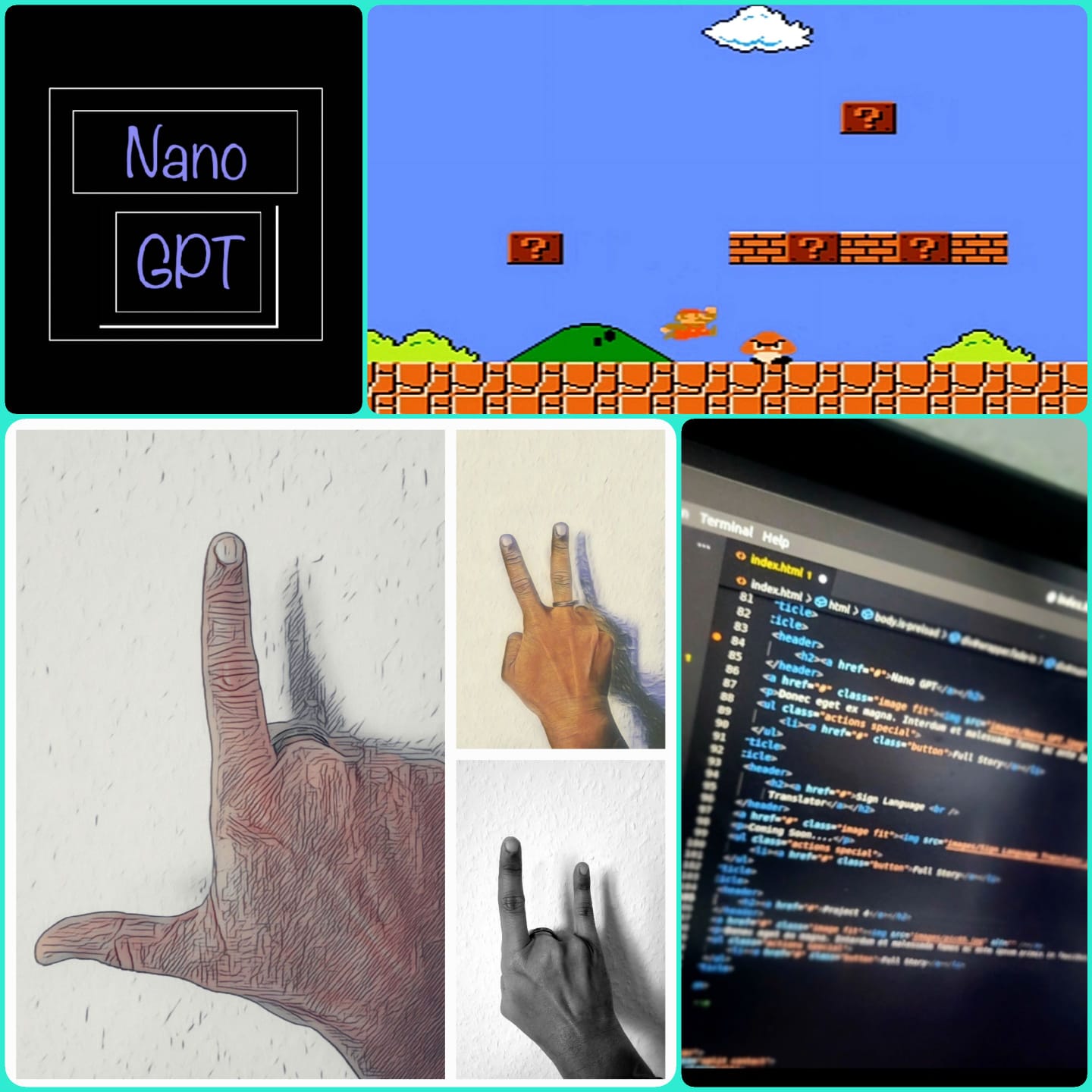
The Reinforcement Learning(RL) Model was built using the Proximal Policy Optimization (PPO) Algorithm and the OpenAI Gym environment. An RL model is a model in which our agent(Mario) will interact with the environment and learn a strategy to get the highest cumulative reward possible.
This is a basic version of a GPT (Generative Pretrained Transformer) model. It is based on the same Transformer architecture, which consists of a self-attention layer and a feed-forward neural network. It was pretrained to generate text autoregressively, meaning it generates one token at a time based on the previously generated tokens.
The basic idea as of now is to create a sign language translator that could translate in real-time and that could be leveraged further to complete German Sign Language or Deutsche Gebärdensprache(DGS). The data was collected through short videos in which I performed the gestures of 3 common words in our day-to-day life in Germany.
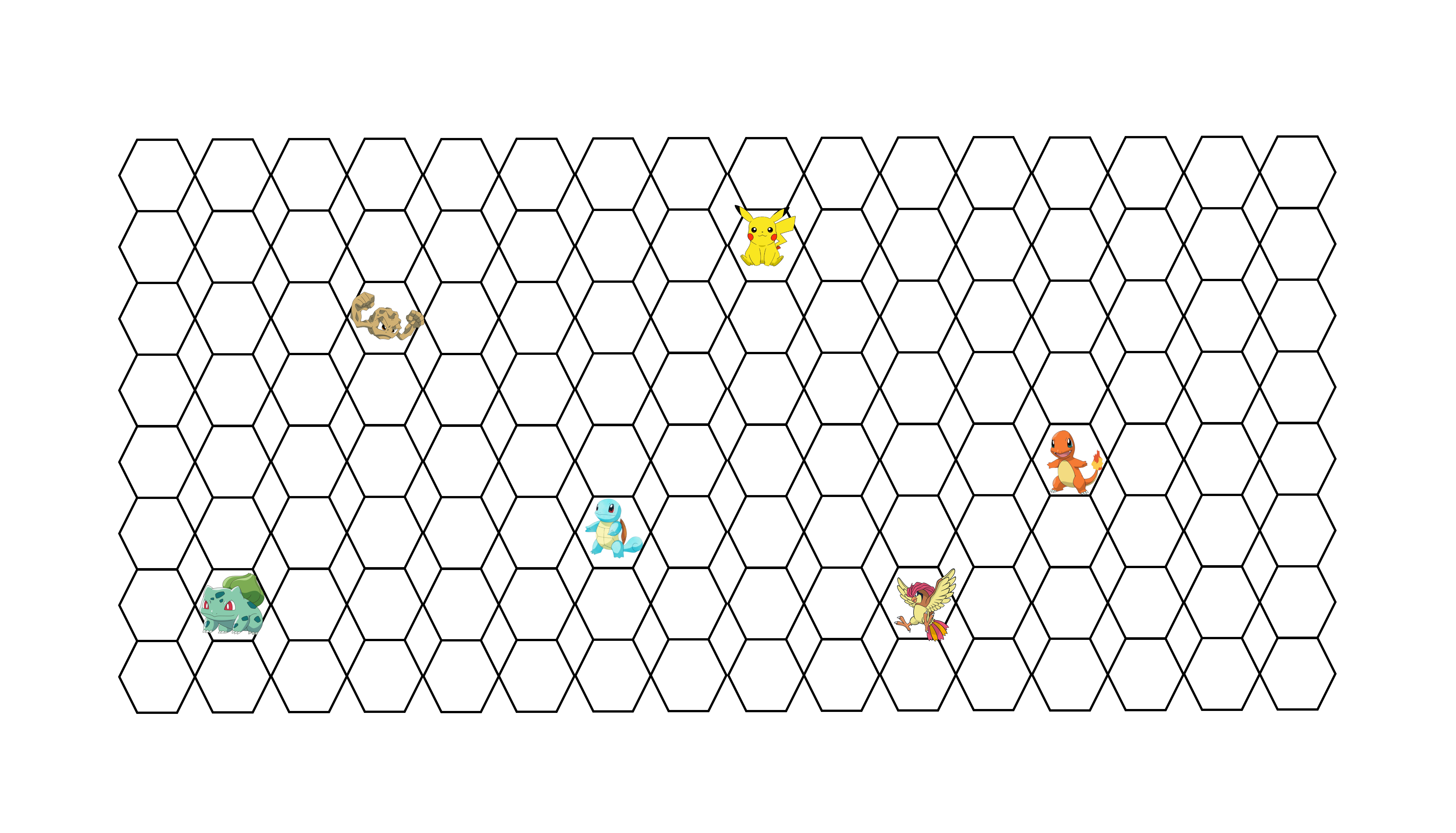
A form of cellular automata simulation, where the Pokemon move and interact based on simple rules about their types. These interactions between Pokemons lead to complex and dynamic patterns, demonstrating the principles of cellular automata.
This project demonstrates how to track a ball in a video showcasing a Tennis game by training a custom YOLO detection model. The model is trained not only for ball detection but also uses interpolation to handle areas where the tracking fails.
The goal of the project is projection of 3D Camera Points onto the 2D images of each camera and finally create a Bird's Eye View (BEV) representation by combining the projected points from all cameras onto a single 2D grid. The BEV provides a top-down view of the scene, which is crucial for tasks like object detection, tracking, and path planning in autonomous driving and robotics.
This project demonstrates a complete pipeline on how to reconstruct a 3D model from a single 2D image using deep learning. It leverages a pre-trained depth estimation model from Hugging Face and the Open3D library for 3D processing, the script takes a 2D image as input, estimates its depth map, generates a 3D point cloud, and finally reconstructs a 3D mesh.
If you want to build a portfolio website similar to my this website then see the complete information about the project by clicking on the above image or the below button.